Dynamically manage your video
Zype's secure CMS makes it easy to manage videos and live broadcasts. Quickly import your content from MRSS feeds, cloud or on-prem repositories. Create and dynamically update playlists, customize metadata, or apply content and category tags, all from a user-friendly dashboard.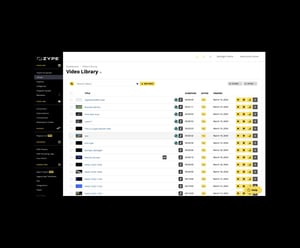
Ensure quality of service
Expand your video platform's reach with confidence. Zype's scalable and reliable platform offers multi-rendition, multi-output encoding and packaging for all video scenarios. Our multi-region cloud hosting solution and global CDN coverage ensures high-availability of your streaming products during peak demand, ensuring a quality streaming experience for your users.
Monetize your way
Zype's integrated CRM provides flexible monetization tools to meet your business model requirements. Offer subscription tiers, rentals, entitlements, PPV events, and downloads for purchase. Preserve ad timings or insert new ones to accommodate your ad strategy. Leverage dynamic ad insertion via Zype SSAI or third-party services. Whether ad supported, subscription based, or transactional, we've got your monetization method covered.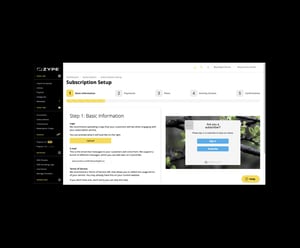
Globally distribute across devices and platforms
Zype Streaming Platform offers reliable distribution of on-demand, live, and linear video on a global scale. Our multi-CDN approach provides expansive geographic coverage across thousands of POPs. Implement geographic restrictions and set content playback rules. Define transcoding and player settings to enable automated adaptive bitrate that services your audience the right video for their device, location and internet connection.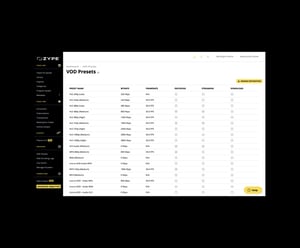
Track audience engagement and performance
User-friendly dashboards allow you to leverage video, consumer, and device-level analytics. Take advantage of Advanced Analytics and download granular reporting so you can optimize your engagement and monetization strategy.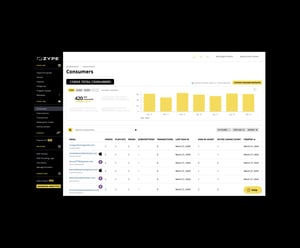
Automate and customize with APIs
Harness an open, API-driven infrastructure that allows for easy integration into your tech stack. Gain control over the whole video lifecycle and automate tasks like encoding, scheduling, and provisioning streams. Build custom experiences and integrations with third-parties and refer to our extensive documentation resources for Developer support.
CASE STUDY
Learn how Andrew Wommack Ministries grew its following with centralized video management.